Underused Kotlin features


Jiří Hutárek
Mobile Software Engineer
Kotlin is a modern and rapidly evolving language. Let's explore some nooks and crannies to see if there are any hidden gems.
Value classes
We often see domain models that look like this:
// DON'T DO THIS!
data class CarCharger(
val id: Long,
val distance: Int,
val power: Int,
val latitude: Double,
val longitude: Double,
val note: String? = null
/* ... */
)
Unfortunately, this antipattern is so widespread that it has earned its own name - primitive obsession. If you think about it, it turns out that in the domain classes that we model based on real business entities, actually, very few things are unbounded Ints, Doubles, or Strings with totally arbitrary content.
The solution is to replace these primitives with proper, well-behaved types - wrapper classes that prohibit invalid values and invalid assignments:
// DON'T DO THIS!
data class Latitude(val value: Double) {
init {
require(value in -90.0..90.0) {
"Latitude must be in range [-90, 90], but was: $value"
}
}
}
We can use this class in the CarCharger instead of the primitive type. This is much better in terms of safety and code expressiveness, but unfortunately it also often results in a noticeable performance hit, especially if the wrapped type is primitive.
But fret not! It turns out that thanks to Kotlin’s value classes, you can have your cake and eat it too! If you slightly modify the class declaration:
@JvmInline
value class Latitude(val value: Double) {
init {
require(value in -90.0..90.0) {
"Latitude must be in range [-90, 90], but was: $value"
}
}
}
the compiler (similarly to what happens with inline functions) will replace the class with the wrapped value at each call site. Thus, at compile-time, we have all the benefits of a separate type, but no overhead at runtime. Win-win! Inline classes also make great database IDs.
Similar to data classes, equals and hashcode are automatically implemented for value classes based on the wrapped value (because value classes have no identity). Value classes can also have many features of standard classes, such as additional properties (without backing fields), or member functions, but there are also some restrictions - they cannot inherit from other classes (they can however implement interfaces), and they must be final.
Be sure to read the full documentation and how value classes in Kotlin relate to Java’s upcoming Project Valhalla.
With consistent use of value classes, your domain models (and other code, of course) can be significantly more secure and readable:
data class CarCharger(
val id: CarChargerId,
val distance: Kilometers,
val power: Kilowatts,
val coordinates: Coordinates,
val note: String? = null
/* ... */
)
Computed properties
Computed properties are properties with custom getter and setter but without a backing field. They can be used to locally "overload" the assignment "operator".
For example, the currently popular reincarnation of the MVVM pattern involves a view model with a public, asynchronous, observable stream of UI states that are continuously rendered by the view. In Kotlin this state stream can be represented by Flow, or more appropriately by its subtype StateFlow, which has some properties more suitable for this situation:
interface ViewModel<S : Any> {
val states: StateFlow<S>
}
Let's create an abstract base class that will serve as the basis for concrete implementations. In order for the view model to update states, it must internally hold a writable version of StateFlow:
abstract class AbstractViewModel<S : Any>(defaultState: S) : ViewModel<S> {
protected val mutableStates = MutableStateFlow(defaultState)
override val states = mutableStates.asStateFlow()
}
If a concrete view model subclass wants to emit a state update based on the previous state, it must do something like this:
class GreetingViewModel : AbstractViewModel<GreetingViewModel.State>(State()) {
data class State(
val greeting: String? = null
/* other state fields */
)
fun onNameUpdated(name: String) {
mutableStates.value = mutableStates.value.copy(greeting = "Hello, $name")
}
}
This works, but the code isn't quite readable, and worse, the implementation details of the abstract view model (that it uses MutableStateFlow internally) leak into the concrete view model - classes must be well encapsulated not only against the outside world but also against their subclasses!
Let's fix this by hiding the MutableStateFlow in the base view model, and instead provide a better abstraction for subclasses:
abstract class AbstractViewModel<S : Any>(defaultState: S) : ViewModel<S> {
private val mutableStates = MutableStateFlow(defaultState)
override val states = mutableStates.asStateFlow()
protected var state: S
get() = mutableStates.value
set(value) {
mutableStates.value = value
}
}
The function in the subclass that needs to update the state then can look like this:
fun onNameUpdated(name: String) {
state = state.copy(greeting = "Hello, $name")
}
The subclass now has no idea how the states are implemented - from its point of view, it just writes and reads the state from a simple property, so if in the future the mechanism for emitting states needs to be changed (and this has happened several times during the development of Kotlin coroutines), individual subclasses will not be affected at all.
Note: The above code is theoretically thread-unsafe, but depending on the context (view model running on the main thread) this may not be an issue.
Pseudoconstructors
In all non-trivial systems, it is important to abstract the object creation process. Although Kotlin must ultimately call a constructor somewhere to create a new instance, this doesn’t mean that all code should be directly coupled to these constructors - quite the opposite. A robust system is independent of how its objects are created, composed, and represented.
Many classic design patterns were created for this purpose, and many of them are still valid with Kotlin, but thanks to the interplay of Kotlin features, we can implement some of them with a twist that improves the discoverability and readability of the resulting code.
When exploring an unfamiliar API, I would argue that the most intuitive way and the first choice to create an object based on its type is to call its constructor.
Creational patterns, however, are meant to abstract concrete constructors away, so in traditional languages we may instead see constructs such as:
Foo.createFoo() Foo.getInstance() Foo.INSTANCE FooFactory.create() Foo.Builder().build() FooBuilder.getInstance().build()
There are many possibilities and combinations, and it can be challenging to keep them all in your head. Luckily, Kotlin can help us!
The first example is a basic factory. Let's say we have a point of interest interface called simply Poi. There are many specific types of POIs with different properties and we need a factory to instantiate them from their serialized representation.
If our factory can be stateless, we can simply create a top-level function of the same name in Kotlin:
fun Poi(serialized: String): Poi
The call site then (except for an import statement maybe) looks exactly the same as if we were calling the constructor.
Moreover, we can do things with top-level functions that we can't do with constructors - for example, we can have such functions in different modules with different visibility and parameters, for different purposes, in different layers, etc., while a constructor always has to live in its own class.
This way we can also create "extension constructors" for types we don't own, for example:
fun ByteArray(base64: String): ByteArray { /* ... */ }
And if our factory function has default parameters, it can also replace simpler builders.
Coroutines library authors do something similar with Jobs. When you write
val job = Job()
what you actually call is this function:
fun Job(parent: Job? = null): CompletableJob = JobImpl(parent)
Here, a "constructor" of a known type actually returns its public subtype, implemented by a private subclass. This gives the library authors a great deal of flexibility for the future.
The second example is more complicated - let's say we've been tasked with creating a year view for a calendar application where workers in a factory can see their shift schedule and other necessary data. The UI looks something like this:
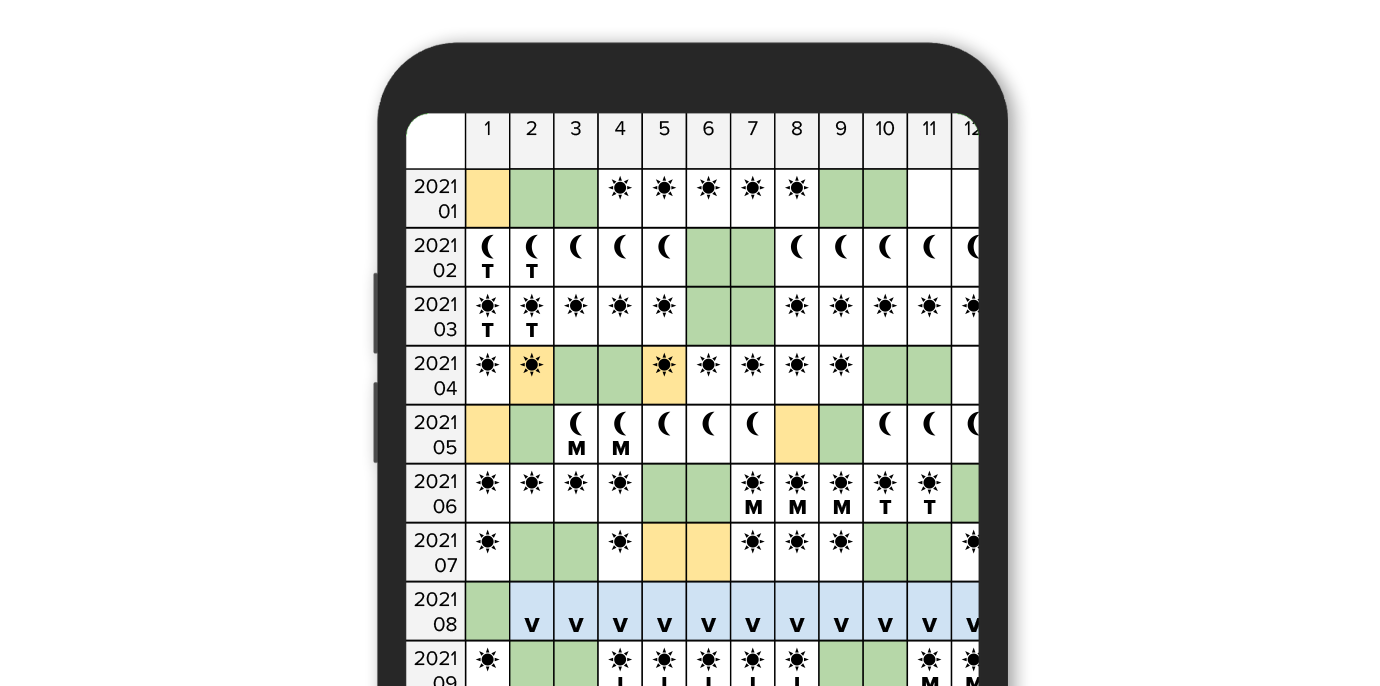
and the domain model of one day is as follows:
data class Day(
val date: LocalDateTime,
val shift: Shift,
val dayType: DayType,
val workType: WorkType
) {
enum class Shift { None, Day, Night }
enum class DayType { Normal, Weekend, NationalHoliday }
enum class WorkType { Normal, Inventory, Maintenance, Training, Vacation }
}
Since the calendar can display several years at once in this view, and there are many possible combinations in each cell, and there can be hundreds of cells on the screen at once, and the whole thing has to scroll smoothly both vertically and horizontally, it is not possible for performance reasons to implement individual cells as regular widgets with an image and a text field.
We need to optimize this UI so that the individual cells are bitmaps that we render directly to the screen. But there would still be hundreds of such bitmaps, and color bitmaps take up a surprising amount of memory surprisingly quickly.
The solution is to cache bitmaps that look the same, effectively making them flyweights. This will save a significant amount of rendering time and memory.
In a classic design, we would create a BitmapFactory, add some BitmapCache, and somehow wire it all together. With Kotlin, we can do this:
class DayBitmap private constructor(val imageBytes: ByteArray) {
/* other properties and methods */
companion object {
private val cache = mutableMapOf<DayCacheKey, DayBitmap>()
private fun Day.cacheKey(): DayCacheKey = ...
private fun Day.render(): ByteArray = ...
operator fun invoke(day: Day): DayBitmap =
cache.getOrPut(day.cacheKey()) { DayBitmap(day.render()) }
}
}
ImageBytes are raw image data that can be directly rendered to the screen. Cache is a "static" global private cache for unique rendered images of days, DayCacheKey is a helper type serving as a key to this cache (Day class cannot be used as a key because it contains a date that is unique for each day - so DayCacheKey uses all the fields from Day except the date).
The main trick is however the invoke operator added to the DayBitmap companion object.
First of all, what happens inside: A cache key is created from the given day, and if we already have a DayBitmap object saved in the cache for this key, we return it immediately. Otherwise, we create it on-demand using its private constructor (which no one else can call!), cache it, and return it immediately. This is the actual flyweight-style optimization.
But the greatest beauty of this approach is in the creation of DayBitmaps. The long version of the call is this:
// DON’T DO THIS! DayBitmap.Companion.invoke(day)
But since we don't have to explicitly state a companion with an implicit name, and the invoke operator just looks like parentheses in a function call, we can shorten the whole thing, and the call-site usage is then indistinguishable from a constructor call, for example
val bitmaps = days.map { day -> DayBitmap(day) }
but with the huge difference that this transformation is internally optimized!
More than the sum of the parts
The charm of Kotlin is often how its individual features can often be used together in somewhat unexpected ways. This was just a small sampling of the less frequent abilities Kotlin has to offer - we'll look at some more next time.
Shift your business forward
Get in contact with us to learn more
about how our IT services can add value to your business.